All Categories
Featured
Table of Contents
Amazon now usually asks interviewees to code in an online document file. Currently that you recognize what questions to expect, let's focus on how to prepare.
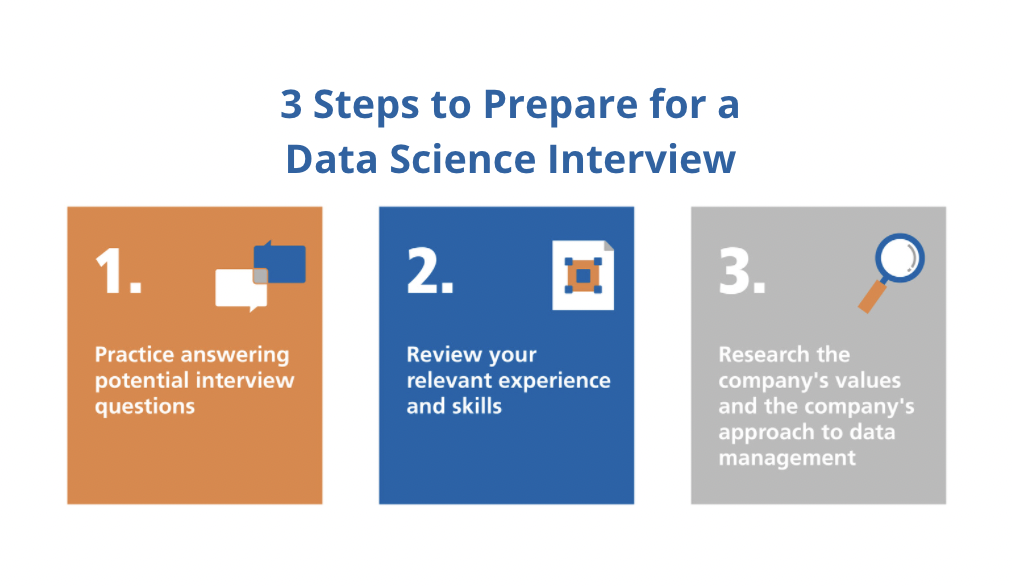
Below is our four-step preparation prepare for Amazon data researcher prospects. If you're planning for even more business than simply Amazon, after that examine our general information science interview prep work guide. Many prospects fail to do this. Before investing tens of hours preparing for a meeting at Amazon, you must take some time to make sure it's really the right firm for you.
Exercise the method utilizing example concerns such as those in section 2.1, or those about coding-heavy Amazon settings (e.g. Amazon software advancement engineer meeting overview). Also, practice SQL and programming questions with tool and tough degree examples on LeetCode, HackerRank, or StrataScratch. Have a look at Amazon's technological topics web page, which, although it's created around software program growth, need to provide you an idea of what they're looking out for.
Note that in the onsite rounds you'll likely have to code on a white boards without being able to execute it, so exercise creating with problems on paper. Supplies free training courses around introductory and intermediate machine discovering, as well as information cleansing, data visualization, SQL, and others.
Pramp Interview
You can publish your own questions and go over subjects likely to come up in your interview on Reddit's stats and artificial intelligence threads. For behavior meeting inquiries, we suggest discovering our step-by-step method for addressing behavior concerns. You can then utilize that technique to practice addressing the example questions offered in Area 3.3 over. Make certain you have at least one story or instance for each of the concepts, from a wide variety of placements and projects. A great means to exercise all of these various types of questions is to interview yourself out loud. This might appear strange, however it will substantially improve the method you communicate your answers throughout a meeting.

One of the major obstacles of information scientist interviews at Amazon is connecting your various responses in a way that's very easy to recognize. As a result, we strongly advise exercising with a peer interviewing you.
They're not likely to have insider expertise of interviews at your target business. For these reasons, many candidates miss peer mock interviews and go directly to mock interviews with a specialist.
Sql Challenges For Data Science Interviews

That's an ROI of 100x!.
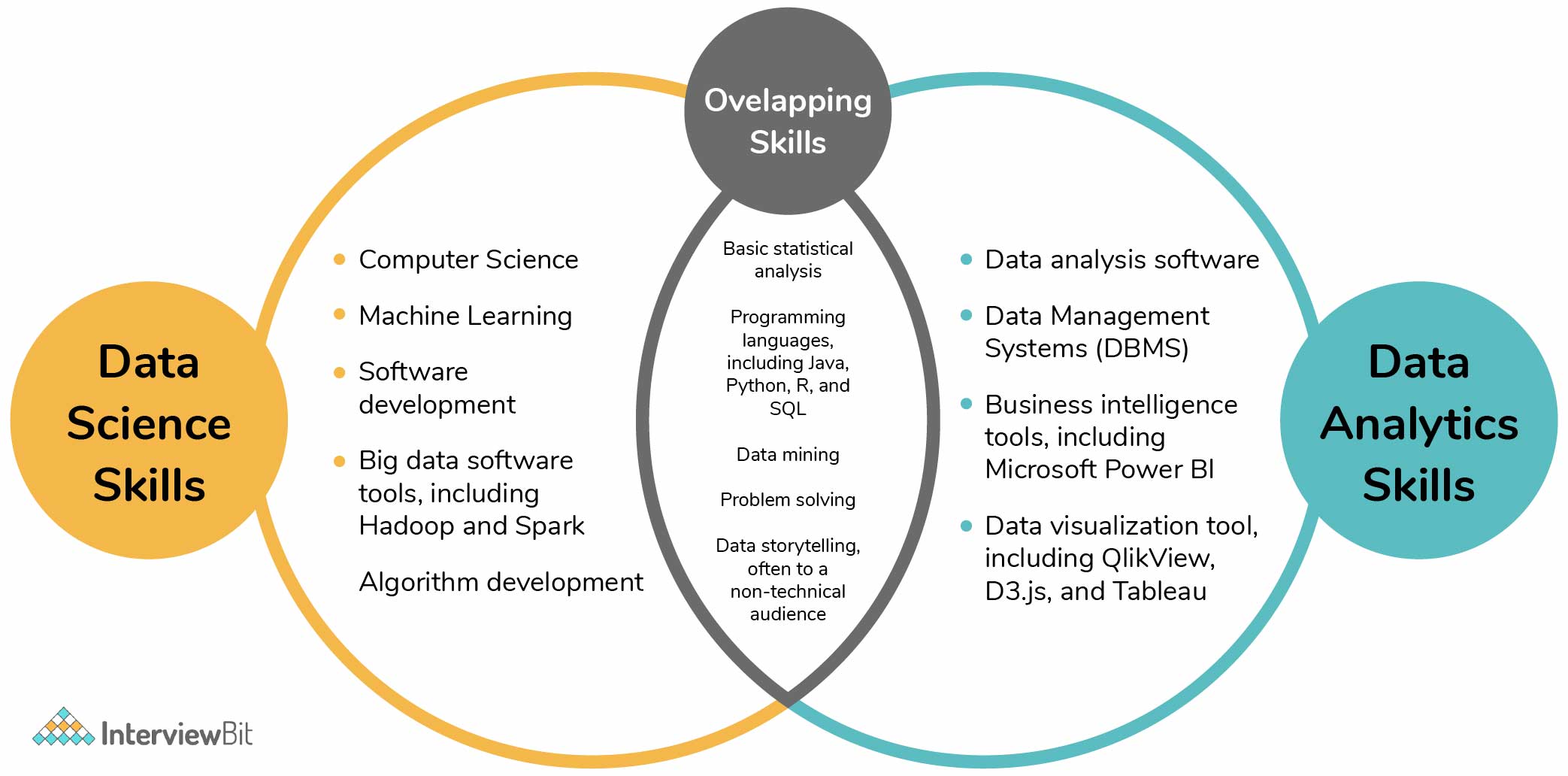
Generally, Data Science would focus on mathematics, computer scientific research and domain name proficiency. While I will briefly cover some computer scientific research basics, the bulk of this blog site will primarily cover the mathematical essentials one could either require to comb up on (or also take an entire training course).
While I understand a lot of you reading this are extra math heavy by nature, recognize the bulk of information scientific research (dare I say 80%+) is accumulating, cleaning and handling information right into a useful type. Python and R are one of the most preferred ones in the Information Scientific research room. I have actually additionally come across C/C++, Java and Scala.
Tech Interview Prep

Typical Python collections of option are matplotlib, numpy, pandas and scikit-learn. It prevails to see the bulk of the data scientists remaining in either camps: Mathematicians and Database Architects. If you are the 2nd one, the blog site will not help you much (YOU ARE CURRENTLY REMARKABLE!). If you are among the initial team (like me), possibilities are you feel that creating a dual nested SQL question is an utter headache.
This might either be collecting sensing unit information, parsing websites or carrying out surveys. After accumulating the data, it requires to be changed into a useful form (e.g. key-value shop in JSON Lines documents). Once the data is gathered and put in a functional style, it is vital to do some information high quality checks.
Faang Interview Preparation Course
In cases of fraudulence, it is really usual to have hefty class discrepancy (e.g. only 2% of the dataset is actual scams). Such information is very important to decide on the suitable selections for attribute design, modelling and design examination. For more info, examine my blog on Fraudulence Discovery Under Extreme Class Discrepancy.
In bivariate analysis, each feature is contrasted to other attributes in the dataset. Scatter matrices permit us to discover concealed patterns such as- features that must be engineered with each other- features that might need to be gotten rid of to avoid multicolinearityMulticollinearity is in fact an issue for multiple models like direct regression and for this reason needs to be taken care of as necessary.
In this area, we will explore some typical feature engineering techniques. Sometimes, the feature on its own might not give valuable information. As an example, picture making use of web use data. You will have YouTube users going as high as Giga Bytes while Facebook Carrier users use a pair of Mega Bytes.
Another problem is using categorical values. While specific values are typical in the information science globe, understand computers can just comprehend numbers. In order for the categorical worths to make mathematical sense, it requires to be transformed into something numeric. Usually for categorical values, it is typical to do a One Hot Encoding.
Scenario-based Questions For Data Science Interviews
At times, having also several sparse measurements will certainly hamper the efficiency of the version. An algorithm generally utilized for dimensionality decrease is Principal Components Analysis or PCA.
The common classifications and their sub classifications are explained in this area. Filter approaches are generally made use of as a preprocessing action.
Common methods under this category are Pearson's Correlation, Linear Discriminant Evaluation, ANOVA and Chi-Square. In wrapper methods, we attempt to utilize a subset of features and train a version utilizing them. Based on the reasonings that we attract from the previous model, we choose to add or remove attributes from your subset.
Machine Learning Case Studies
These approaches are normally computationally very pricey. Typical methods under this group are Onward Selection, Backwards Removal and Recursive Feature Elimination. Embedded methods combine the high qualities' of filter and wrapper techniques. It's implemented by formulas that have their very own built-in function selection approaches. LASSO and RIDGE are usual ones. The regularizations are given up the equations below as referral: Lasso: Ridge: That being claimed, it is to understand the auto mechanics behind LASSO and RIDGE for meetings.
Overseen Discovering is when the tags are available. Unsupervised Knowing is when the tags are inaccessible. Obtain it? SUPERVISE the tags! Word play here planned. That being said,!!! This error is enough for the interviewer to terminate the meeting. Additionally, an additional noob mistake people make is not normalizing the functions prior to running the design.
. Guideline. Straight and Logistic Regression are one of the most fundamental and typically utilized Artificial intelligence algorithms around. Prior to doing any analysis One typical meeting mistake people make is beginning their evaluation with a more complicated version like Semantic network. No doubt, Semantic network is very exact. Nonetheless, benchmarks are very important.
{kind=link}
Table of Contents
Latest Posts
A Comprehensive Guide To Preparing For A Software Engineering Interview
Facebook Software Engineer Interview Guide – What You Need To Know
Atlassian Engineering Interview Handbook – A Complete Prep Guide
More
Latest Posts
A Comprehensive Guide To Preparing For A Software Engineering Interview
Facebook Software Engineer Interview Guide – What You Need To Know
Atlassian Engineering Interview Handbook – A Complete Prep Guide